|
3) 關于雙庫協同機制具體實現的進一步討論。例如:可達關系的概率估計定理:設p>2a+a2/(1-a);對定義的參數b和B, 令a<b<(1-a)p, 令(1-p+pa)/(1-a)<B<1-a. 則隨著論域X的數據庫Â(X)中元組數目S(R)的增加,本原知識庫中每一條正規則對應的數據子類結構庫中的關系為一個可達關系的概率均趨于1;每一條反規則對應的關系為非可達關系的概率均趨于1。
1.2.2雙基融合機制 (兩個知識發現過程間的內在聯系)
雙庫協同機制給出了特定結構下數據庫與知識庫的對應關系,那么基于數據庫的KDD與基于知識庫的KDK的兩個發現過程有無內在聯系呢?我們得到了肯定的回答。
我們發現了表面上毫無關聯的兩個知識發現過程(KDD與KDK)的內在聯系;雙基融合機制將兩者統一在一個知識發現系統(過程)中,使其相輔相成,是一種機器智能的較高境界。設計了R型協調器、S型協調器與T型協調器,解決了KDK依賴與部分地轉化為KDD的難題。該項內容已正式申報國家發明專利《一種融入R型協調器的KDK系統》(200510086965.8)、《一種融入R型與S型協調器的KDK系統》(200510086964.3)和《一種基于雙基融合機制的的KDK*系統》(200510086966.2)(見附件 )。
1)(KDD與KDK)過程模型邏輯等價定理:設KDK的過程模型為M=,KDD的過程模型為N =,在依數據子類結構構建數據庫,依知識結點網絡構建知識庫的條件下,M與N各要素間建立了一一對應關系,即M與N邏輯等價。其中:Q為結點集,R為認知通達關系,f為正則測度函數,g為正則確信度函數;S為數據子類集,F為可達性關系,Sup為數據子類的支持度,Vel為F上的挖掘可信度。
依據該定理,我們可將部分KDK挖掘問題轉化為KDD的挖掘問題;同時為規則驗證提供了轉換的根據。
2) 雙基融合機制的實現:構造了R型、S型、T型三個協調器,并設計了相應的軟件。
1.2.3信息擴張機制 (動態挖掘進程規律)
目前的挖掘算法與評價方法的討論基本上是在一個時間剖面上,相對穩定的狀態下進行的,而對于動態挖掘進程、實時與在線的挖掘進程考慮得較少;擴散、演化與預測性研究日趨重要。信息擴張機制主要指當數據挖掘過程從一個抽象級向下一個抽象級、從固有數據庫(知識庫)向擴展數據庫(知識庫)過渡的時候,所呈現的運行規律。如:規則價值的動態評價、類似于"不動點"的數據簇的尋求、"突變"協調算法、基于知識信息熵的預覽算法、數據挖掘復雜性研究等問題。得到的主要結果如下:
1) 動態挖掘進程中規則參數的演化規律的研究:
基于認知物理學的“語言場”與“信息擴散原理”,發現了關聯規則的特類——意外規則參數演化的規律;
參數演化定理:在KDD的動態挖掘進程中的某一時間段內,在對實時數據庫DB實施分庫和每種參數只考慮上升、平行、下降三種演化情況的前提下,對于意外規則而言,其組.態空間可劃歸為S={<0,0,0,0,0>, <0,0,0,1,-1>, <0,0,0,-1,1>, <-1,0,-1,0,0>, <-1,0,-1,1,-1>, <-1,0,-1,-1,1>, <0,1,-1,0,1>, <0,1,-1,-1,1>, <0,1,-1,1,0>, <0,1,-1,1,1>, <0,1,-1,1,-1>, <-1,1,-1,0,1>, <-1,1,-1,-1,1>, <-1,1,-1,1,0>, <-1,1,-1,1,1>, <-1,1,-1,1,-1>}。
該定理將1024種參數演化的組態情況化歸為16種(波動型除外,對于波動型利用“信息擴散原理”加以討論),并給出了被認為是知識發現難點的可理解性討論的5類主題分析。
對于波動型的討論:規則的參數波動變化的情況有781種,對參數波動變化的態勢可采用下述的方法處理----信息擴散原理是一種在樣本不足的情況下,對樣本應遵循的規律進行認識的模糊數據處理方法。我們提出的自動評價方法可在領域專家不介入的情況下,利用知識(規則)的可計算參數進行評價;并由信息擴散原理彌補參數相對不足的缺陷,得到規則參數的概率分布信息,據此客觀地展現規則特征,從而實現規則評價。
2) 矛盾域分布的研究:
定義 設在對真實數據庫的動態挖掘時,規則的兩個參數(支持度和可信度)的閾值
設為 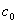 和 和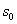 若下列兩參數聯立不等式: 若下列兩參數聯立不等式:
① 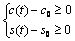 ② ②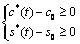
有解。則稱所求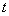 的區間(或點集)為矛盾域。其中 的區間(或點集)為矛盾域。其中 、 、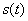 為三維空間中規則兩參數對 為三維空間中規則兩參數對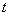 的函數。 的函數。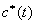 、 、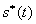 為對應矛盾規則(滿足矛盾規則概念模型)對的函數。 為對應矛盾規則(滿足矛盾規則概念模型)對的函數。
定理 研究數據挖掘中矛盾規則的問題,可以抽象為在一個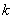 維向量空間 維向量空間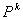 中,求解規則(比如產生式規則P→Q)與其對應的受矛盾規則概念模型約束的矛盾規則(P→┒Q)的參數向量同時落在閾值空間 中,求解規則(比如產生式規則P→Q)與其對應的受矛盾規則概念模型約束的矛盾規則(P→┒Q)的參數向量同時落在閾值空間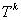 中的問題。 中的問題。
3) 變論域下閾值設置的研究:
一般方法是先在數據屬性論域中,討論實際數據庫中數據項目屬性的特征,進行模
糊綜合評判,確定各個項目客觀合理的最小支持度閾值(為“點值”類閾值);然后在時空論域中,從數據庫本身的動態變化中尋找變化規律,使用閾值協調器計算規則的基礎的閾值取值區間;最后確定變論域下閾值設置的輸出函數( 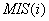 )。用戶只需依照該閾值設置函數對閾值進行設置,將可以達到我們客觀合理地設置閾值的目的確。 )。用戶只需依照該閾值設置函數對閾值進行設置,將可以達到我們客觀合理地設置閾值的目的確。
4) 知識發現系統中信息熵方法的應用研究:
理論物理研究的成果表明,熱力學熵適合于研究海量粒子的分布規律。現代信息論在通訊等領域的成功應用表明,信息熵適用于研究人們有效獲取知識或信息的方法。
定理:如果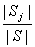 表示任何一個元素在 表示任何一個元素在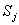 中出現的概率, 中出現的概率,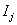 是對中的任何一個元 是對中的任何一個元
素分類所需要的平均信息量,則對樣本空間中任一個元素分類所需要的信息量為:
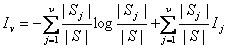
這個結論比ID3算法的理論分析結果多出了一項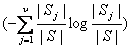 。 。
此可克服ID3算法傾向于屬性值較多的屬性的缺陷。
信息熵一般表達式:我們應用所建立的關于概念及其分解的符號體系得到了樹形概念分解之下,基于任何概念粒度的信息熵(信息蘊含量)的一般表達式
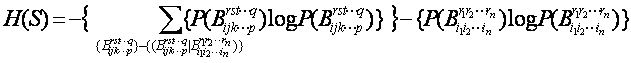 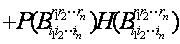
上一頁 [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] 下一頁
|